Download
Click here to access Google Drive which contains the full dataset (about 6.86GB).
Directory Structure
|
|-- 01/ # directory for Seq. #01 data
| |
| |-- prebuilt/ # seq. for creating prebuilt map
| | |-- video_pers.mp4 # video captured with perspective model
| | └-- poses.txt # ground-truth poses
| |
| └-- input/ # seq. for LC-VSLAM input
| |-- video_pers.mp4 # video captured with perspective model
| └-- poses.txt # ground-truth poses
|
└-- 02/ (or 03/ - 12/) # directory for Seq. #02 (or #03 - #12) data
|
|-- prebuilt/ # seq. for creating prebuilt map
| |-- video_pers.mp4 # video captured with perspective model
| |-- video_fish.mp4 # video captured with fisheye model
| |-- video_equi.mp4 # video captured with equirectangular model
| └-- poses.txt # ground-truth poses
|
└-- input/ # seq. for LC-VSLAM input
|-- video_pers.mp4 # video captured with perspective model
|-- video_fish.mp4 # video captured with fisheye model
|-- video_equi.mp4 # video captured with equirectangular model
└-- poses.txt # ground-truth poses
Description
We made this dataset with CARLA Simulator. Using urban models (Town02 - Town05) provided by CARLA, we manually steered a car on which a virtual camera is mounted, then recorded an image sequence and a ground-truth trajectory. We captured the sequences using three types of projection models: perspective, fisheye, and equirectangular (except for Seq. #01). Also, each of the sequences has two videos, prebuilt and input, that have some overlaps between them so that they constitute a looping trajectory. Prebuilt ones are used for prebuilt-map creation in our paper, and input ones are for input to LC-VSLAM.
In the following, details on intrinsic parameters, video format, and ground-truth trajectory format are presented.
Subsequently, information of each of the sequences is also listed.
For each of the projection models, we provide projection parameters, which are needed to reproject a camera-referenced 3D point onto an image plane.
There are four pinhole-projection parameters for the perspective model.
Note that there is neither radial nor tangential distortion parameter.
There are four fisheye-projection parameters for the fisheye model.
Note that there is no distortion parameter.
Intrinsic Parameters
Perspective
Seq. fx fy cx cy cols rows
#01 320 320 320 180 640 360
#02 - #12 640 640 640 360 1280 720
The projection process can be described by the following pseudo-code:
fx, fy: focal lengths (in pixel unit) for x- and y-axescx, cy: principal points (in pixel unit) for x- and y-axescols, rows: horizontal and vertical image size (in pixel unit)
a = Xc / Zc
b = Yc / Zc
x = fx * a + cx
y = fy * b + cy
[Xc, Yc, Zc] is a camera-referenced 3D coordinates of a 3D point.
Fisheye
Seq. fx fy cx cy cols rows
#02 - #12 586 586 640 360 1280 720
The projection process can be described by the following pseudo-code:
fx, fy: focal lengths (in pixel unit) for x- and y-axescx, cy: principal points (in pixel unit) for x- and y-axescols, rows: horizontal and vertical image size (in pixel unit)
a = Xc / Zc
b = Yc / Zc
r = sqrt(a * a + b * b)
theta = atan(r)
x = fx * (theta / r) * a + cx
y = fy * (theta / r) * b + cy
[Xc, Yc, Zc] is a camera-referenced 3D coordinates of a 3D point.
Equirectangular
There are no intrinsic parameters for the equirectangular model. Only the image size is needed for the projection process.| Seq. | cols | rows |
|---|---|---|
| #02 - #12 | 2160 | 1080 |
cols,rows: horizontal and vertical image size (in pixel unit)
l = sqrt(Xc * Xc + Yc * Yc + Zc * Zc)
bx = Xc / l
by = Yc / l
bz = Zc / l
latitude = -asin(by)
longitude = atan2(bx, bz)
x = cols * (0.5 + longitude / (2 * PI))
y = rows * (0.5 - latitude / PI)
[Xc, Yc, Zc] is a camera-referenced 3D coordinates of a 3D point.
Video
All of the videos are recorded in H.264 YUV420p format whose framerate is 30.0 FPS.
Ground-truth Poses
All of the trajectory files are formatted in a similar manner as the ones of KITTI dataset. Each line in the trajectory file represents a camera-referenced SE3 camera pose in raw-major format, and the line number corresponds to the frame number of the video.
For example, assume that the following values are written at the N-th line of ./01/prebuilt/poses.txt.
A set of these values represents the ground-truth camera pose of the N-th frame of ./01/prebuilt/video_pers.mp4.
r_11, r_12, r_13, t_1, r_21, r_22, r_23, t_2, r_31, r_32, r_33, t_3
These values can be interpreted as a camera-referenced SE3 camera pose Twc, which converts a 3D point in the N-th camera coordinates to the one in the world coordinates.
Twc = [
[r_11, r_12, r_13, t_1],
[r_21, r_22, r_23, t_2],
[r_31, r_32, r_33, t_3],
[ 0, 0, 0, 1]
]
The following is an example of coordinate transformation, where X_c and X_w represent the camera- and world-referenced homogeneous coordinates of a 3D point, respectively.
X_w = T_wc @ X_c
Sequence List
| Seq. | Length (prebuilt) | Length (input) | Resolution | Trajectory | Direct Link | CARLA world |
|---|---|---|---|---|---|---|
| #01 | 1:07 | 1:04 | Perspective: 640x360 |
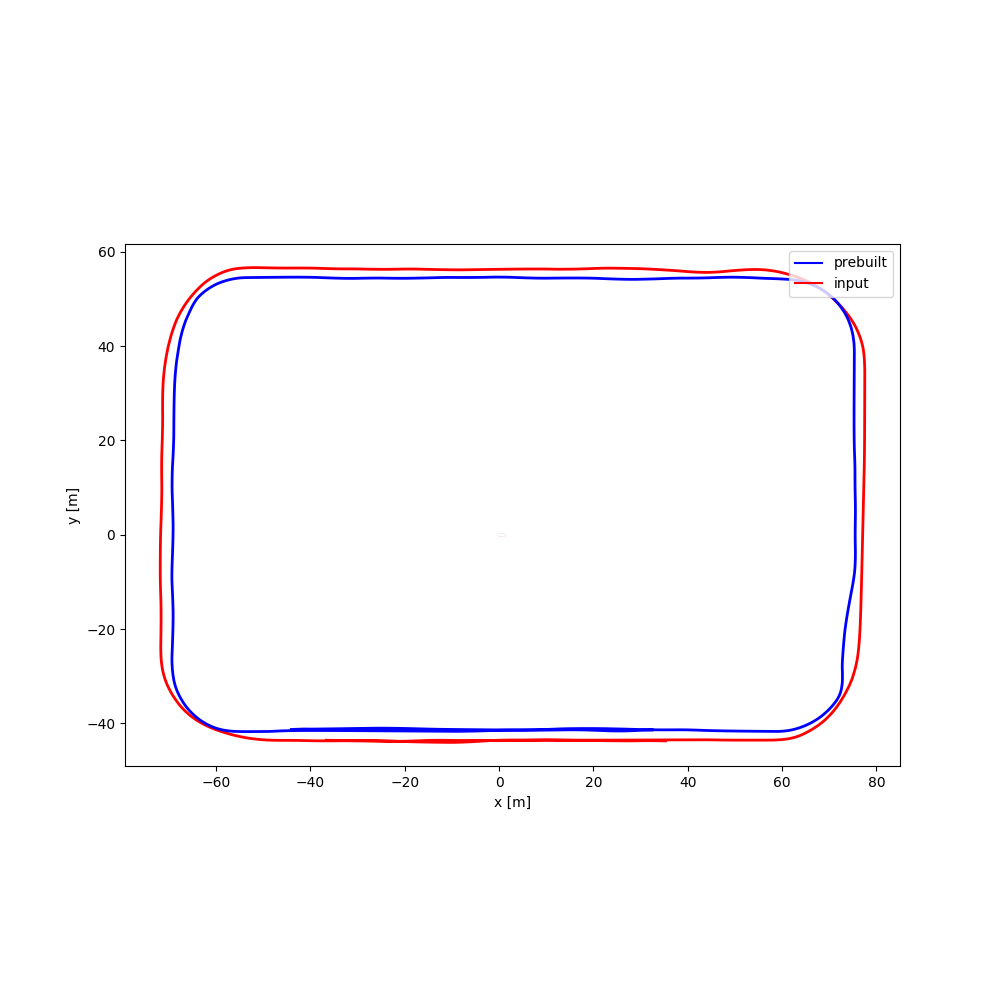 |
[Google Drive] | Town05 |
| #02 | 2:20 | 1:16 | Perspective: 1280x720 Fisheye: 1280x720 Equirectangular: 2160x1080 |
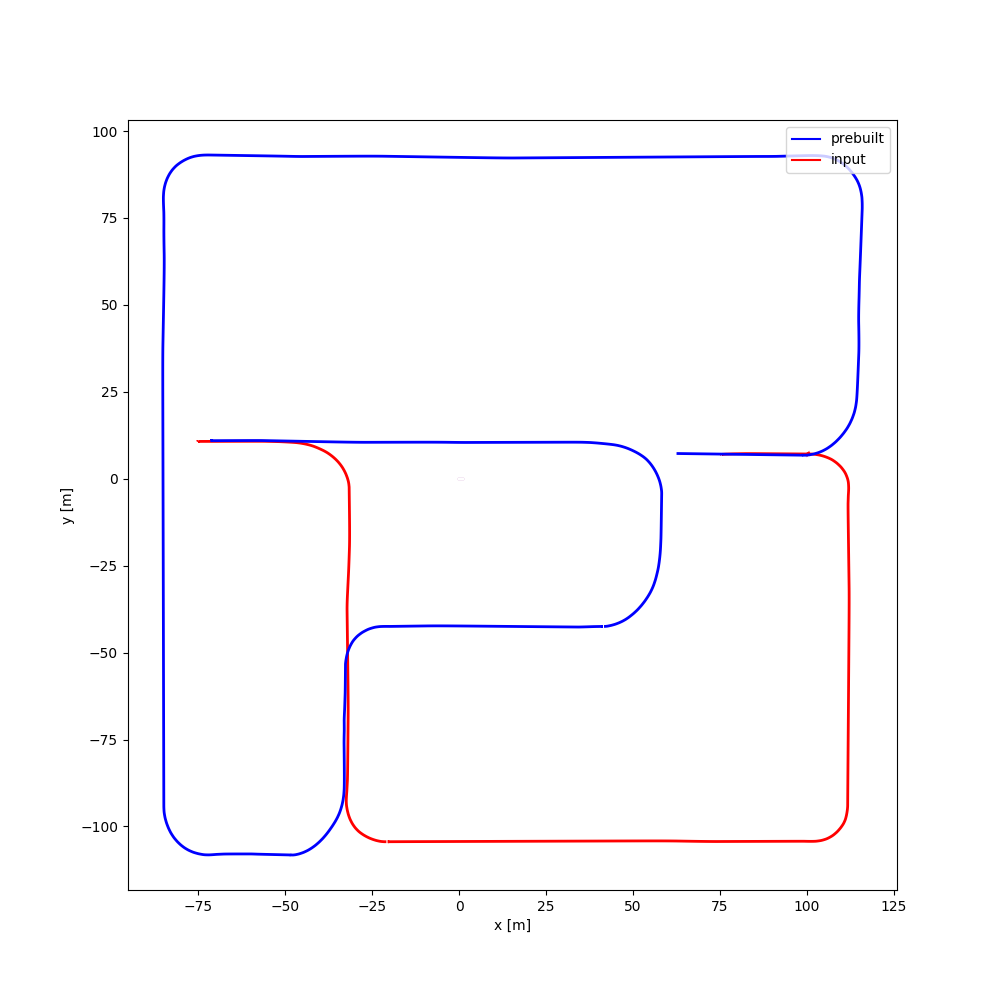 |
[Google Drive] | Town02 |
| #03 | 2:08 | 1:28 | 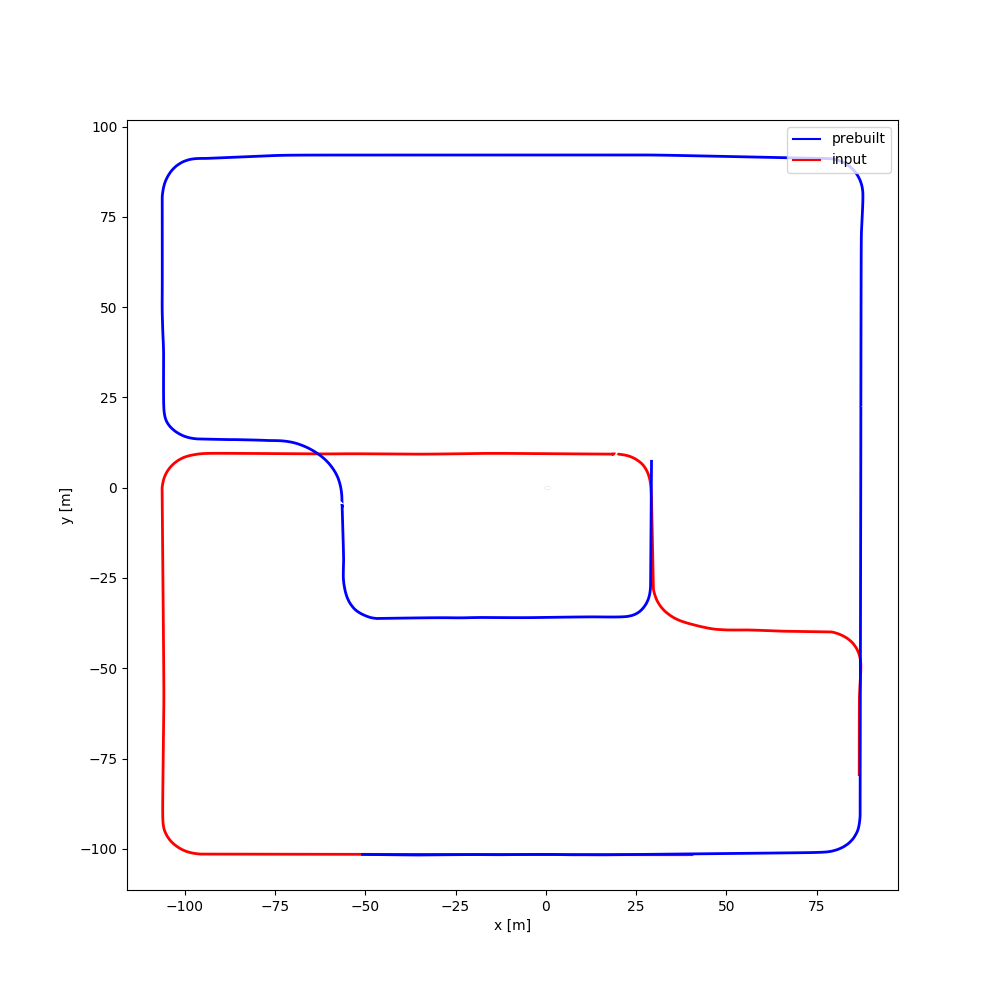 |
[Google Drive] | Town02 | |
| #04 | 1:40 | 1:49 | 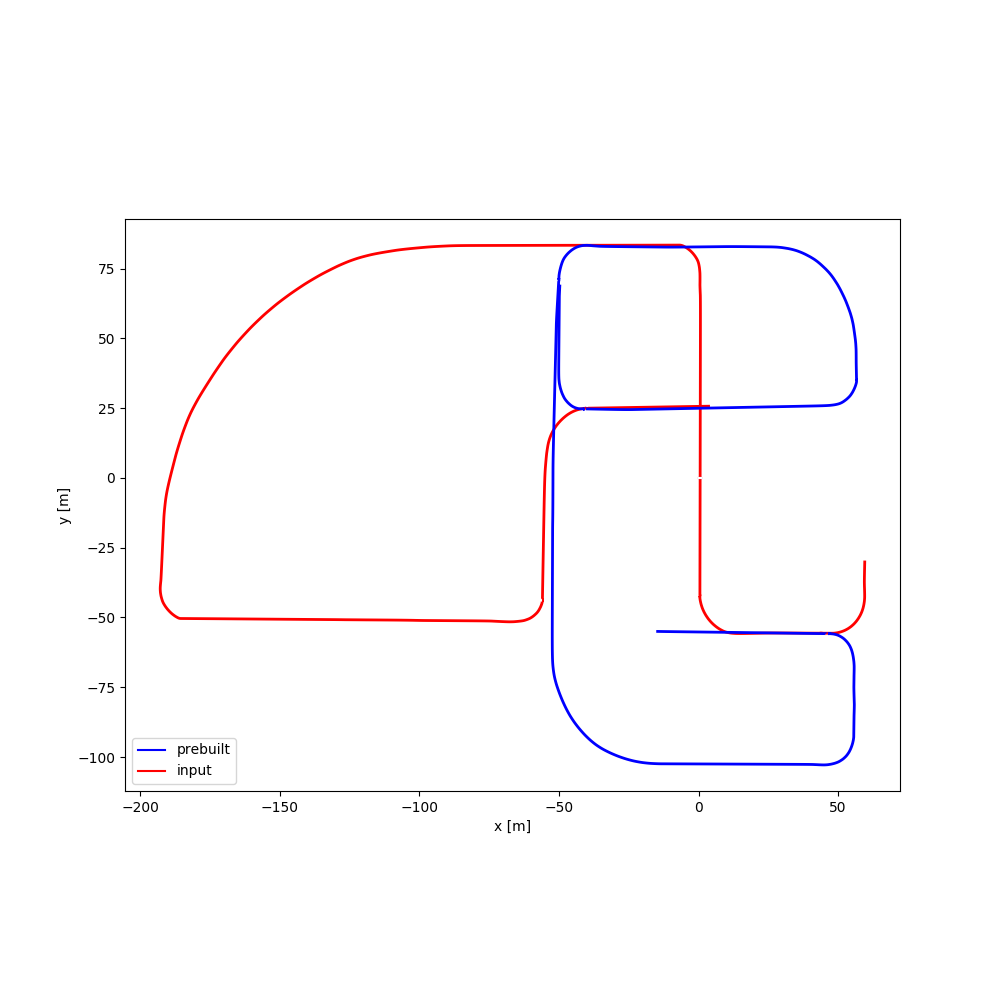 |
[Google Drive] | Town04 | |
| #05 | 2:11 | 1:34 | 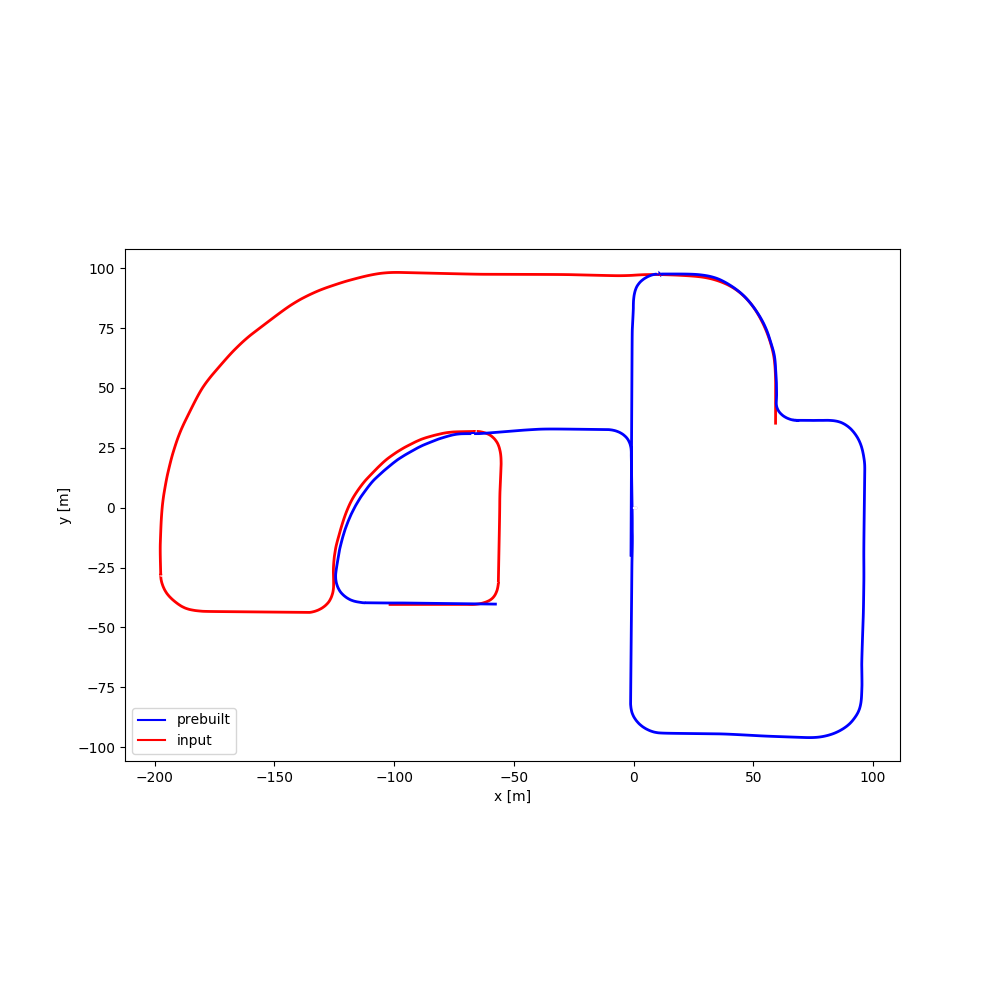 |
[Google Drive] | Town04 | |
| #06 | 2:47 | 1:34 | 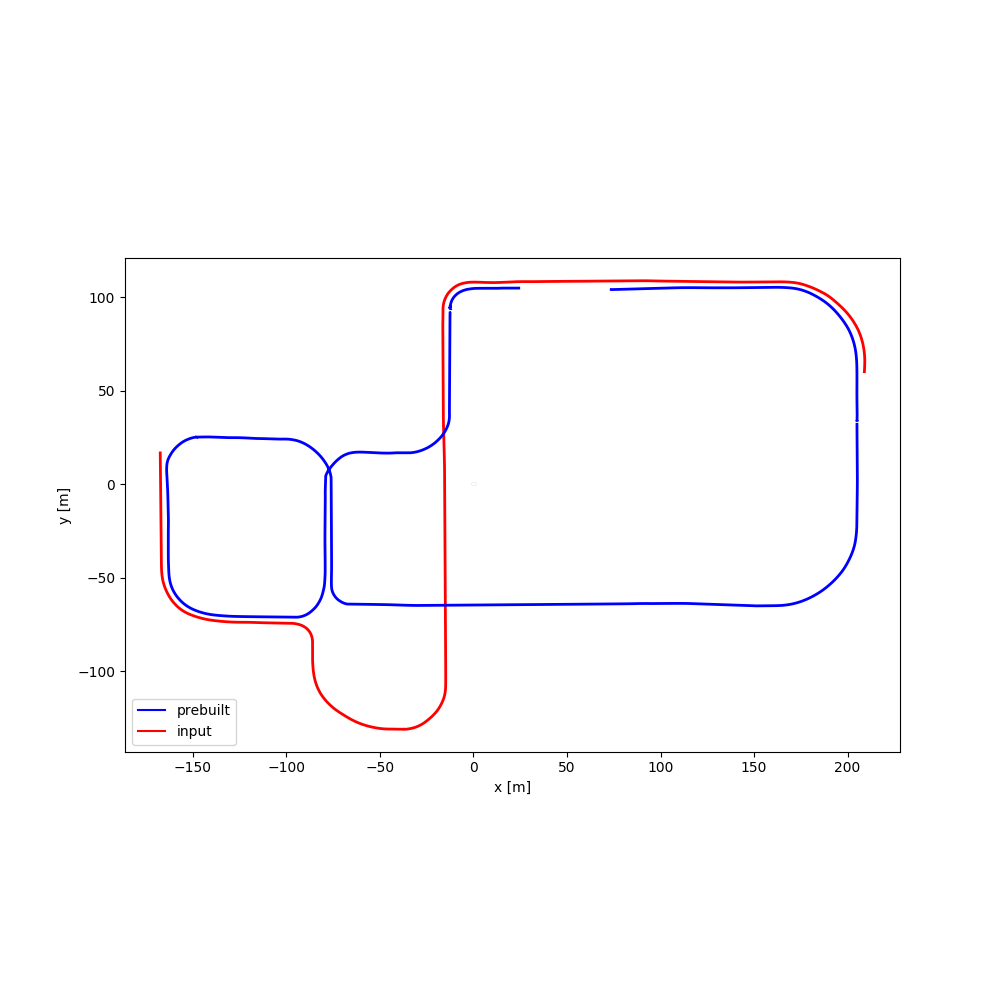 |
[Google Drive] | Town05 | |
| #07 | 2:20 | 2:00 | 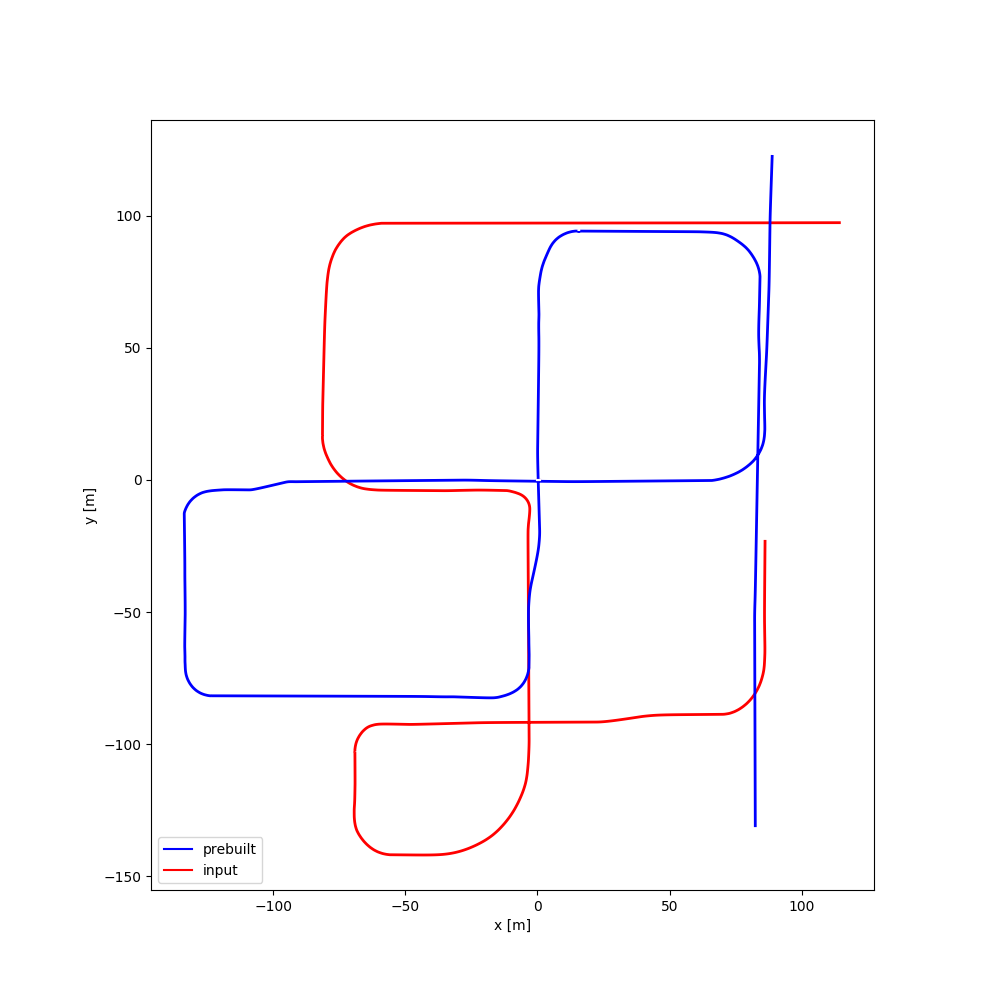 |
[Google Drive] | Town05 | |
| #08 | 2:21 | 2:04 | 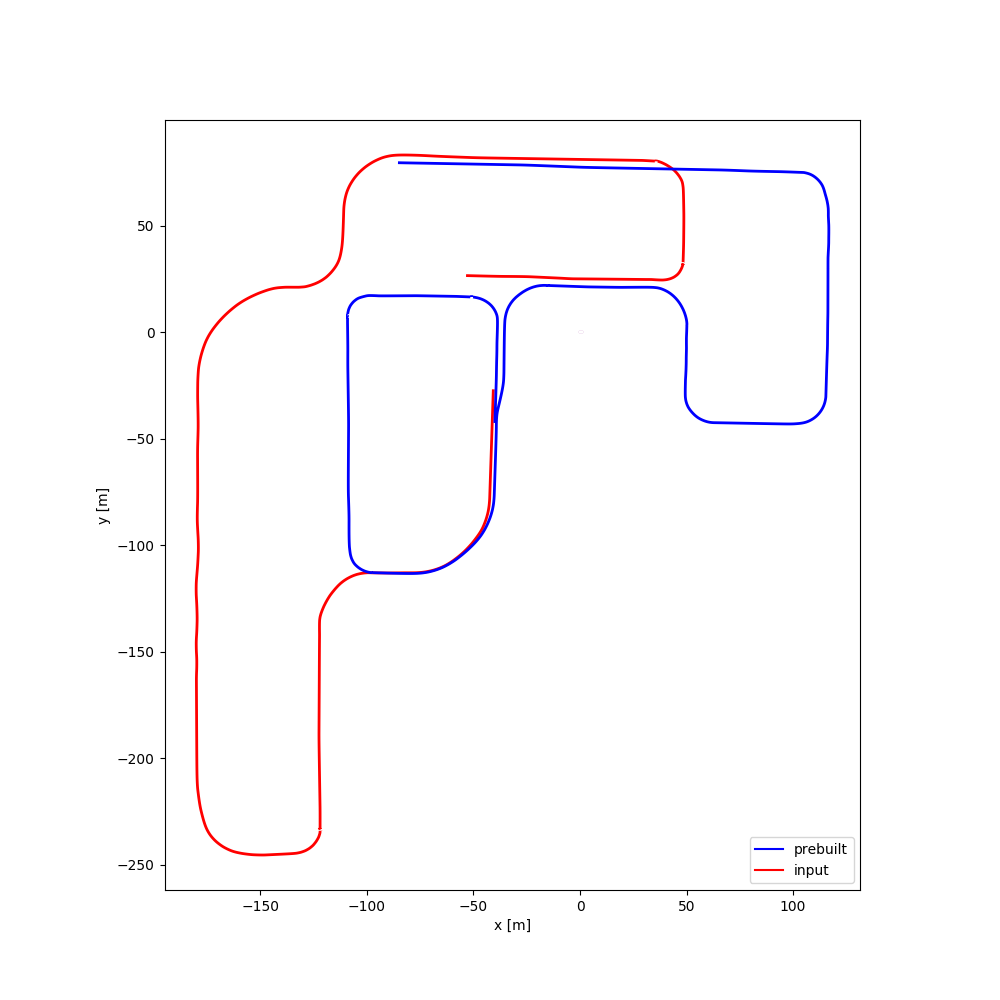 |
[Google Drive] | Town03 | |
| #09 | 2:26 | 1:58 | 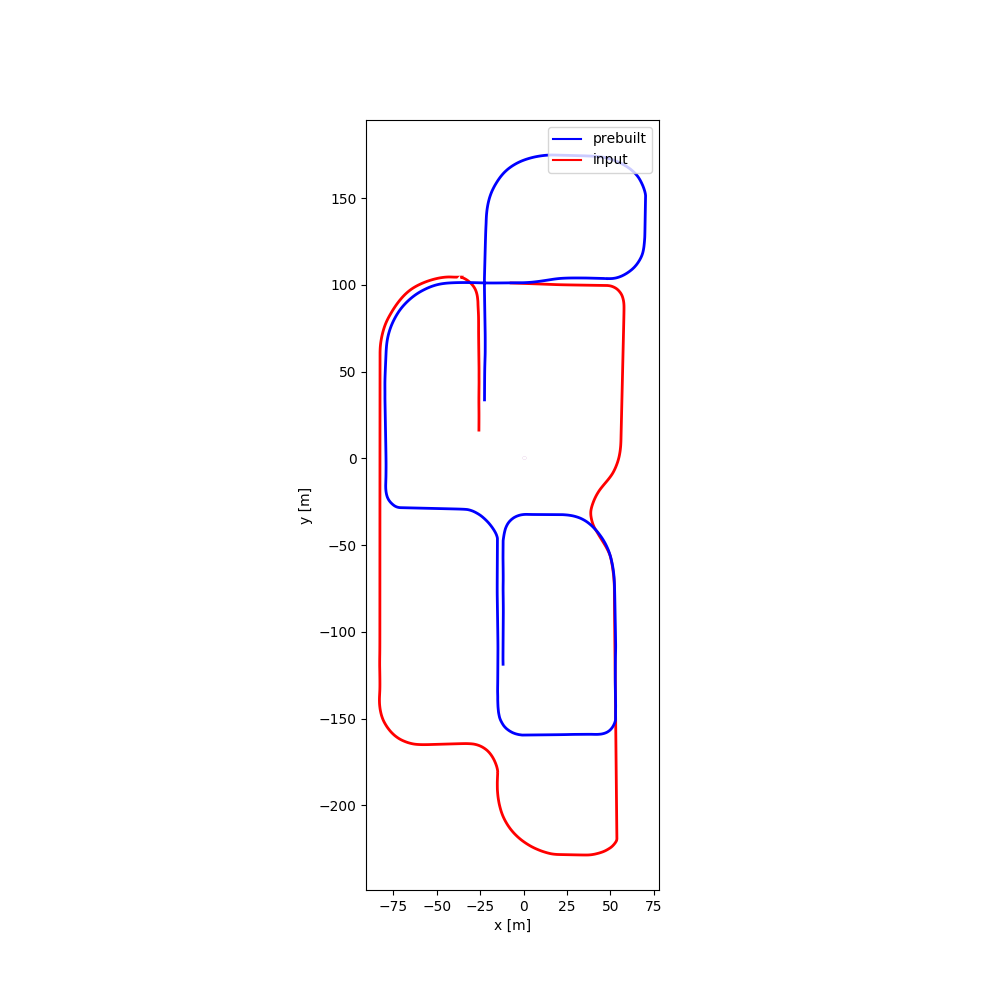 |
[Google Drive] | Town03 | |
| #10 | 2:45 | 3:46 | 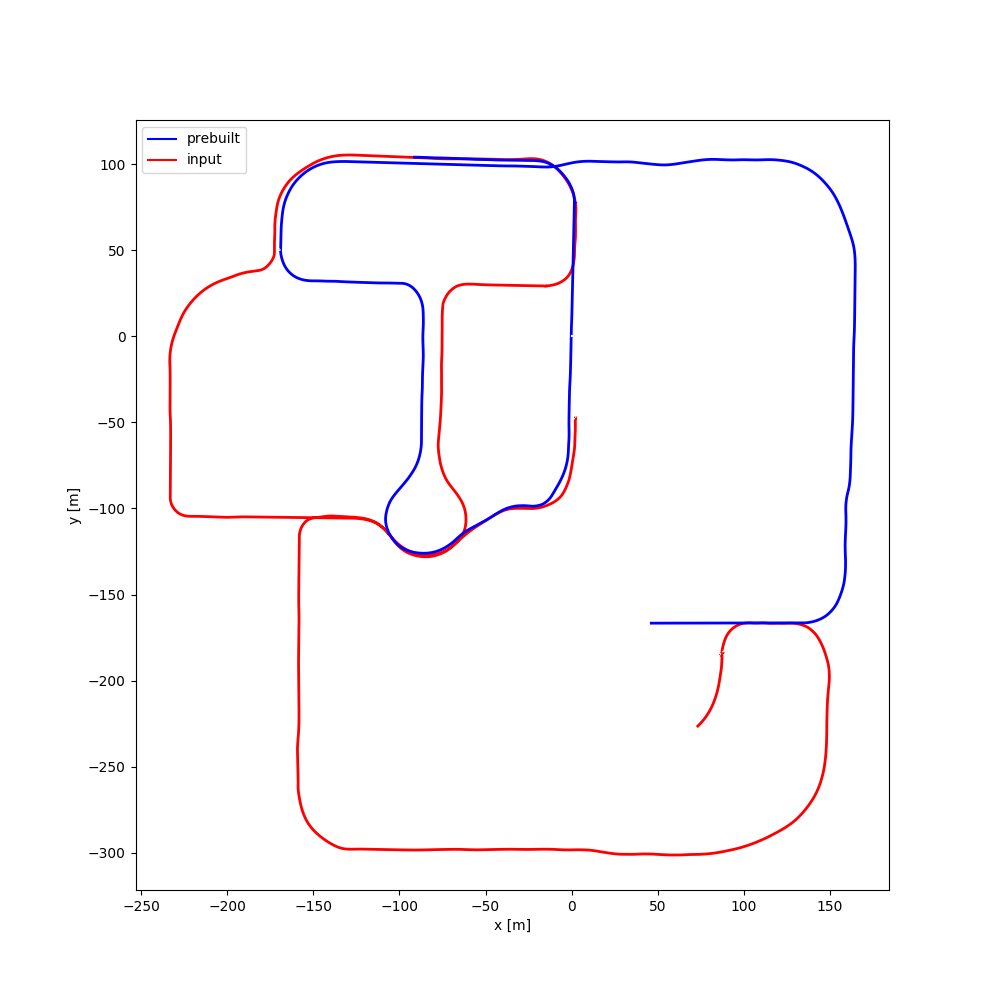 |
[Google Drive] | Town03 | |
| #11 | 2:56 | 2:53 | 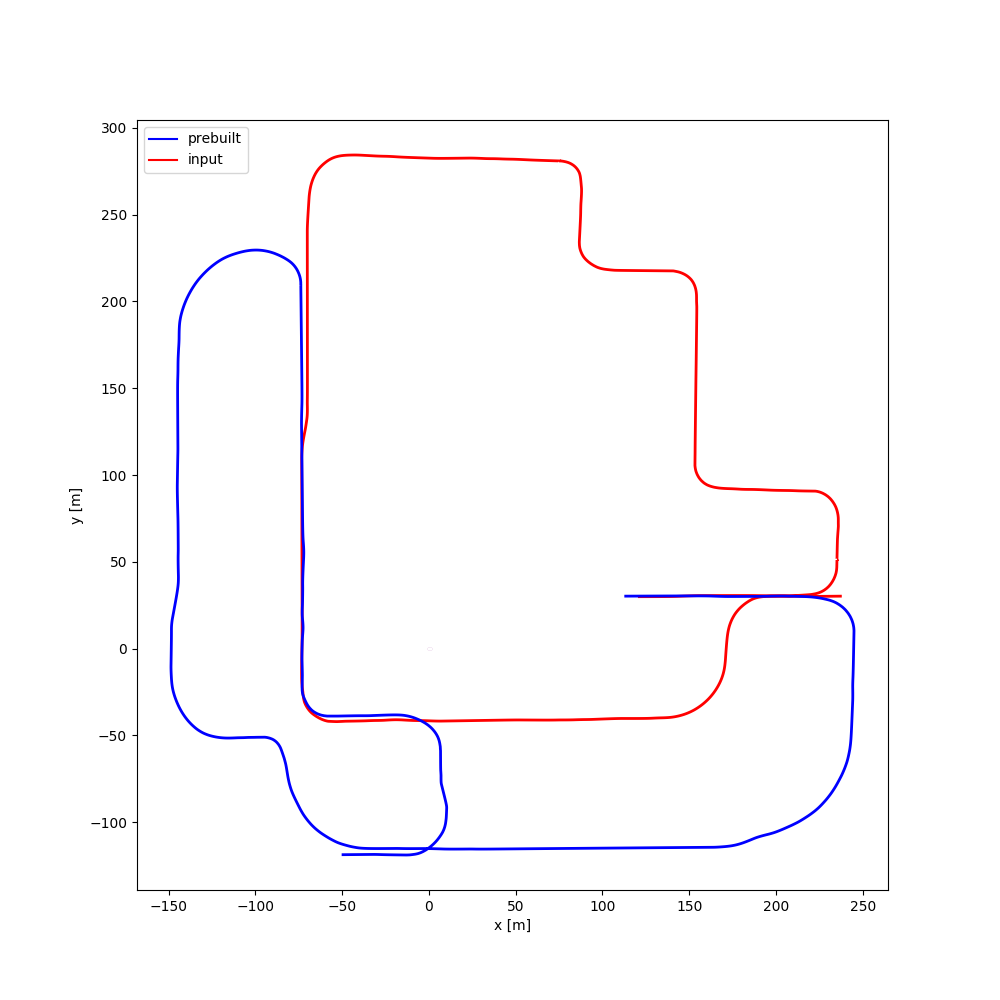 |
[Google Drive] | Town03 | |
| #12 | 2:23 | 2:17 | 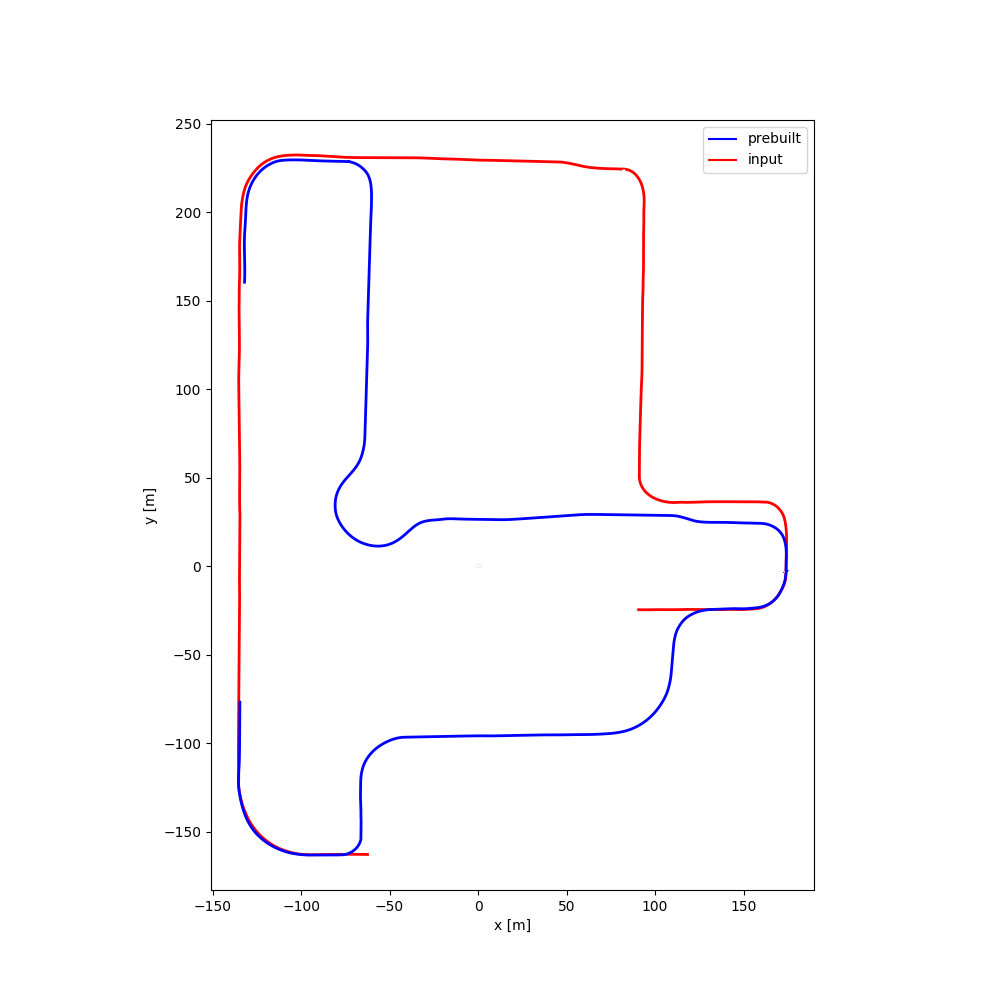 |
[Google Drive] | Town03 |
Citation
@inproceedings{shibuya2020privacy,
title = {Privacy Preserving Visual {SLAM}},
author = {Mikiya Shibuya and Shinya Sumikura and Ken Sakurada},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
Contact
- Mikiya Shibuya: shibuya.m.ab <at> m.titech.ac.jp
- Ken Sakurada: k.sakurada <at> aist.go.jp