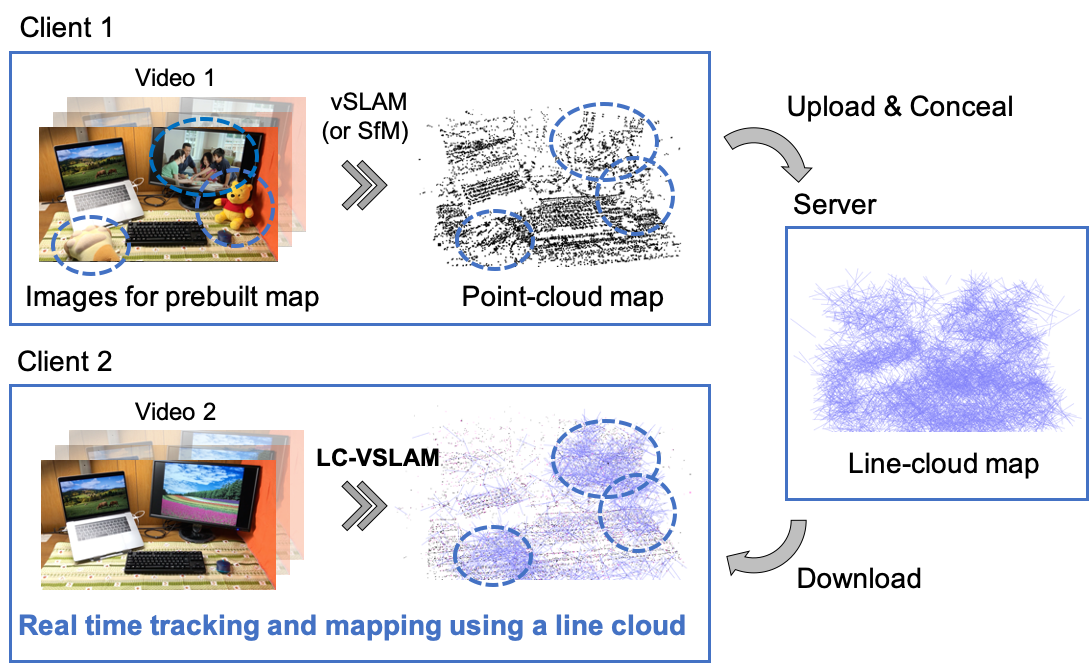
Preliminary
Inversion Attack
Pittaluga et al. proved that fine images at arbitrary viewpoints can be restored only from a sparse point cloud and its optional attributes [Pittaluga et al., CVPR'19]. They referred to this restoration as the inversion attack. Thus, in AR/MR applications, there is a risk of privacy leak, which is caused by restoring confidential information from a shared point cloud by using the inversion attack.

3D Line Cloud
To prevent the inversion attack, a map representation based on a 3D line cloud is proposed [Speciale et al., CVPR'19]. The line cloud is built by converting each 3D point to a 3D line that has a random orientation and passes through the original point. It is difficult to directly restore the original point cloud from the line cloud because the point coordinates can be reparameterized arbitrarily on the corresponding line.
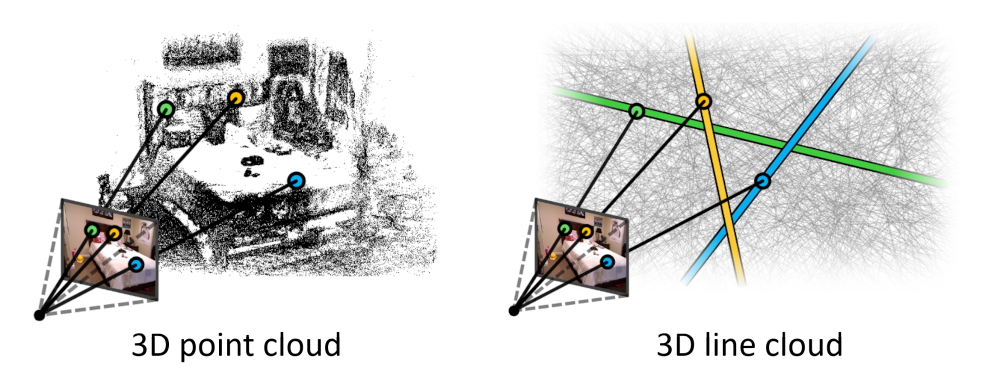
In addition, they also formulated a method for localizing an image in the prebuilt line-cloud. On the other hand, however, there has been no Visual SLAM algorithm that can estimate camera poses continuously and in real-time using a line cloud.
LC-VSLAM
We propose a Visual SLAM framework for real-time relocalization, tracking, and bundle adjustment (BA) with a map mixed with lines and points, which we call Line-Cloud Visual SLAM (LC-VSLAM). The main contributions of this study are three-fold:
- Efficient relocalization and tracking methods which utilize both 3D points reconstructed on a client and 3D lines sent from a server
- Motion-only, rigid-stereo, local, and global BAs for mixed line and point clouds
- Creation of a unified framework for various types of projection models, such as perspective, fisheye, and equirectangular
Experimental Results
These are qualitative evaluation in which LC-VSLAM applied to fisheye and equirectangular videos.
Each of the datasets contains two videos.
One is used for building a line cloud.
The other is used for tracking in the prebuilt line cloud and mapping unobserved areas.
Please see the teaser video for the perspective one.
NOTE: In the videos, lines are drawn as line "segments" for better visibility, but actually they do not have any ends.
Fisheye (CARLA)
Equirectangular (Campus)
Quantitative Evaluation
Localization
This is a comparison of one-shot localization performance from the viewpoints of tracking time of each frame, absolute pose errors (APEs). LC-VSLAM outperforms the previous method in terms of both consumed time and localization accuracy.
| Tracking time [ms] | APE trans [m] | APE rot [deg] | |
|---|---|---|---|
| p6L [Speciale et al.] | 140.3 | 0.7815 | 0.5896 |
| LC-VSLAM (ours) | 31.09 | 0.1979 | 0.2841 |
Tracking Accuracy
This is a comparison of APEs between the two types of the prebuilt map: 3D point cloud and line cloud. Even when using a 3D line cloud as a prebuilt map, LC-VSLAM achieves comparable performance to the conventional one using a 3D point cloud.
| APE trans [m] / rot [deg] | CARLA Perspective | CARLA Fisheye | CARLA Equirectangular | KITTI |
|---|---|---|---|---|
| point-cloud map | 3.290 / 0.6273 | 2.883 / 0.4402 | 3.079 / 0.2375 | 3.801 / 1.012 |
| line-cloud map (ours) | 3.651 / 0.8416 | 3.177 / 0.5941 | 3.075 / 0.2766 | 4.488 / 1.309 |
Map Optimization Efficiency
The performance of the proposed global map optimization is also confirmed. APEs are compared under the three conditions: w/o global optimization, w/ the pose-graph optimization (PGO), and w/ the PGO and the global BA. The PGO and the global BA efficiently reduces errors of estimated trajectories.
| APE trans [m] / rot [deg] | CARLA Perspective | CARLA Fisheye | CARLA Equirectangular |
|---|---|---|---|
| None | 24.06 / 1.292 | 10.16 / 1.064 | 14.28 / 3.682 |
| w/ PGO | 3.301 / 1.151 | 1.670 / 0.8039 | 9.640 / 2.790 |
| w/ PGO & global BA | 3.018 / 1.100 | 1.593 / 0.8525 | 8.320 / 2.404 |
Citation
@inproceedings{shibuya2020privacy,
title = {Privacy Preserving Visual {SLAM}},
author = {Mikiya Shibuya and Shinya Sumikura and Ken Sakurada},
booktitle = {European Conference on Computer Vision (ECCV)},
year = {2020}
}
Contact
- Mikiya Shibuya: shibuya.m.ab <at> m.titech.ac.jp
- Ken Sakurada: k.sakurada <at> aist.go.jp